主题
- #最近鄰搜尋 (最近鄰搜尋)
- #相似度搜尋
- #數據分佈
- #向量搜尋 (Vector Search)
- #高維空間
撰写: 2024-11-23
撰写: 2024-11-23 17:13
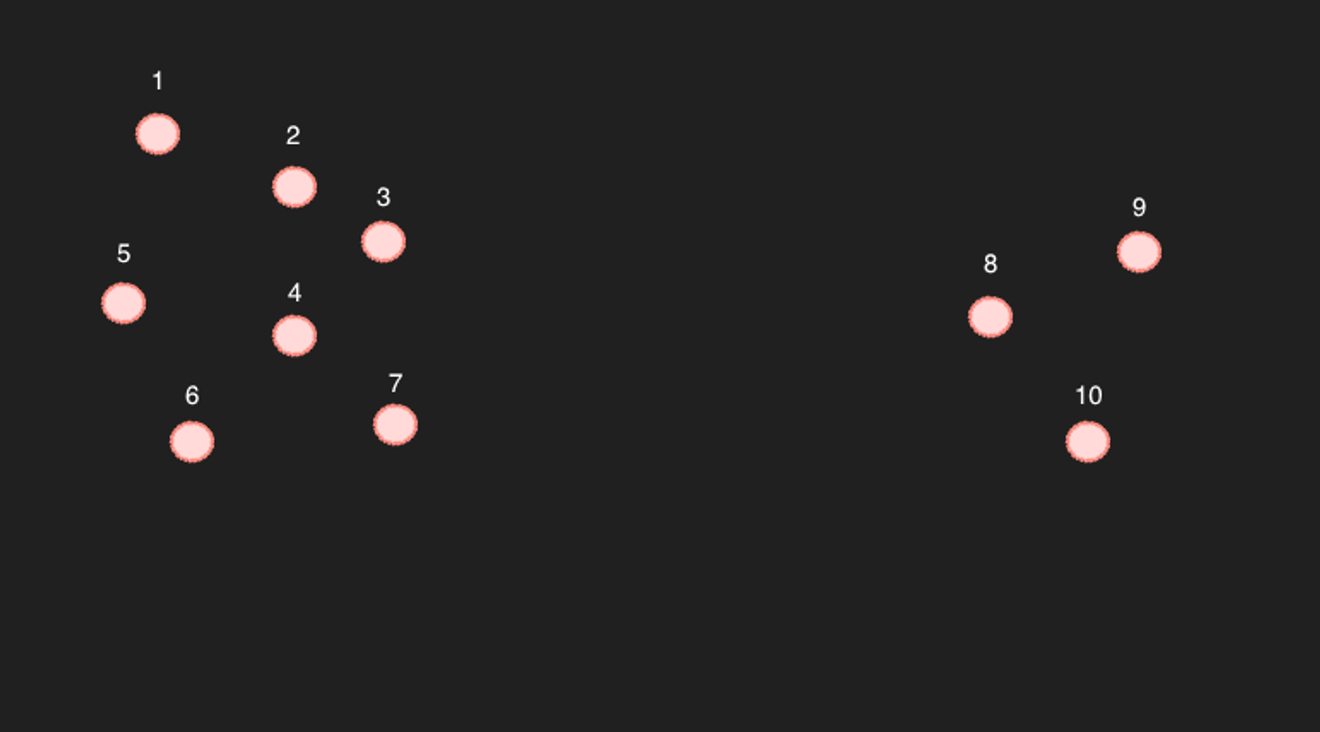
分散的樣本
向量搜尋 (以下簡稱搜尋) 的基本原理是透過各種數學方法找出距離最近的項目。
但是,我突然產生了一個疑問。最近鄰搜尋雖然正確且符合數學原理,但它真的能找到相似的文章嗎?
實際上,杜魯米斯(durumis) 使用的搜尋方法是在 768 維空間中搜尋與目標文章最接近的 6 篇文章。
然而,我開始懷疑這些搜尋結果是否真的相似。(因為偶爾會出現不相似的文章……)
那麼,原因是什麼呢?
讓我們以簡化的二維空間中的 10 個點為例。
1 到 7 號點,如果選擇最近的 6 個點,其餘 6 個點肯定會是最接近的點。(實際計算結果也是如此)
問題在於 8 到 10 號點……例如,如果搜尋 9 號點最近的 6 個點,結果可能是 8、10、以及 3、4、7。
這樣就有問題了,反過來,在 4 號點中,最近的 6 個點不包含 9 號點,那麼它們真的是相關文章嗎?
上面的例子是一個相當極端的案例,如果存在足夠多的點,使得空隙不那麼大,那麼就可以將其視為足夠接近。(但是,考慮到 768 維空間,中間不可避免地會存在空隙。除非有非常大量的文章……)
我正在思考這個問題,最確定的方法是,如果文章數量足夠多,這個問題就能解決吧?
2024年6月18日
2024年9月6日
2024年3月13日
2025年1月2日
2024年3月29日
2024年7月9日
评论0