Chủ đề
- #Phân bố dữ liệu
- #Không gian đa chiều
- #Tìm kiếm gần nhất
- #Tìm kiếm tương đồng
- #Tìm kiếm Vector
Đã viết: 2024-11-23
Đã viết: 2024-11-23 17:13
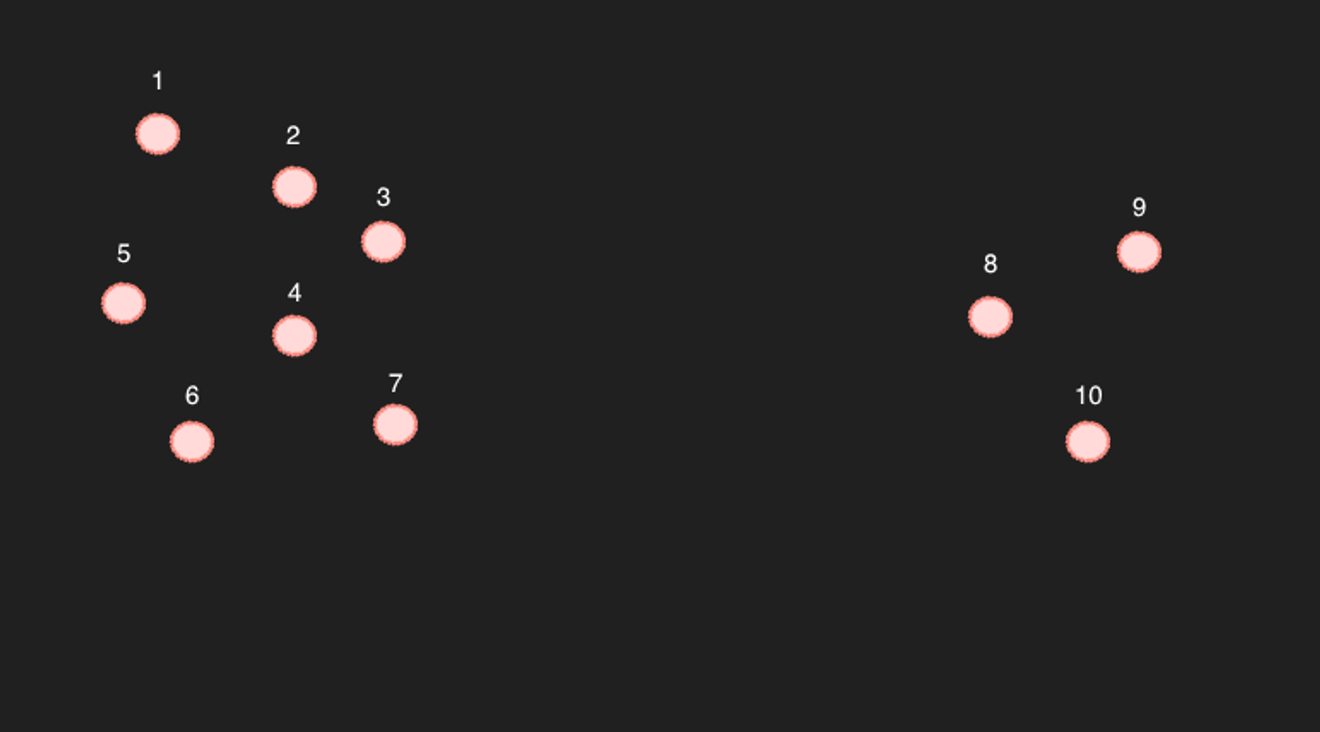
Ví dụ về sự phân tán
Nguyên lý cơ bản của Tìm kiếm Vector (sau đây gọi là tìm kiếm) là tìm các đối tượng ở khoảng cách gần nhau thông qua nhiều phương pháp toán học khác nhau.
Tuy nhiên, tôi tự hỏi. Liệu tìm kiếm gần nhất có thực sự chính xác và đúng về mặt toán học, nhưng liệu nó có thực sự là bài viết tương tự không?
Trên thực tế, tìm kiếm được sử dụng trong durumis (두루미스) là tìm kiếm 6 bài viết gần nhất trong không gian 768 chiều của một bài viết.
Nhưng tôi bắt đầu đặt câu hỏi liệu các bài viết tương tự có thực sự là tương tự không. (Vì đôi khi có những bài viết không giống nhau...)
Vậy lý do là gì?
Hãy lấy ví dụ về 10 điểm trong không gian hai chiều được đơn giản hóa ở trên.
Đối với các điểm từ 1 đến 7, nếu chọn 6 điểm gần nhất, thì 6 điểm còn lại chắc chắn sẽ là các điểm gần nhất. (Trên thực tế, điều này cũng đúng về mặt tính toán)
Vấn đề là ở các điểm từ 8 đến 10... Ví dụ: nếu tìm kiếm 6 điểm gần nhất của điểm số 9, thì kết quả có vẻ sẽ là 8, 10 và 3, 4, 7.
Nhưng vấn đề là, ngược lại, trong 6 điểm gần nhất của điểm số 4, điểm số 9 không được bao gồm, vậy liệu chúng có thực sự là các bài viết liên quan không?
Ví dụ trên là một trường hợp cực đoan, nhưng nếu có đủ điểm để không gian trống không quá rộng, thì có thể coi chúng là gần nhau. (Tuy nhiên, nếu xét đến chiều 768, thì chắc chắn sẽ có khoảng trống ở giữa. Trừ khi có rất nhiều bài viết...)
Tôi đang suy nghĩ về vấn đề này, nhưng cách chắc chắn nhất là vấn đề này sẽ được giải quyết nếu có đủ bài viết?
April 26, 2024
June 18, 2024
January 18, 2025
September 4, 2024
March 13, 2024
April 11, 2024
Bình luận0