หัวข้อ
- #การค้นหาเวกเตอร์ (Vector Search)
- #การค้นหาที่ใกล้ที่สุด (최근접 검색)
- #การกระจายข้อมูล (데이터 분포)
- #การค้นหาความคล้ายคลึงกัน (유사도 검색)
- #พื้นที่มิติสูง (고차원 공간)
สร้าง: 2024-11-23
สร้าง: 2024-11-23 17:13
ตัวอย่างการกระจาย
พื้นฐานของการค้นหาแบบเวกเตอร์ (ต่อไปนี้คือ การค้นหา) คือการค้นหาสิ่งต่างๆ ที่อยู่ใกล้กันโดยใช้หลายวิธีทางคณิตศาสตร์
แต่ฉันก็สงสัยขึ้นมาทันที การค้นหาที่ใกล้ที่สุดนั้นถูกต้องและถูกต้องทางคณิตศาสตร์ แต่สิ่งนี้คือบทความที่คล้ายกันหรือไม่?
ในความเป็นจริง การค้นหาที่ใช้ใน durumis (두루미스) นั้นเป็นวิธีการค้นหา 6 บทความที่ใกล้ที่สุดในพื้นที่ 768 มิติของบทความหนึ่งๆ
แต่ฉันก็เริ่มสงสัยว่าบทความที่คล้ายกันนั้นเป็นบทความที่คล้ายกันจริงๆ หรือไม่ (เพราะบางครั้งบทความที่ไม่คล้ายกันก็ปรากฏขึ้น...)
แล้วสาเหตุคืออะไร?
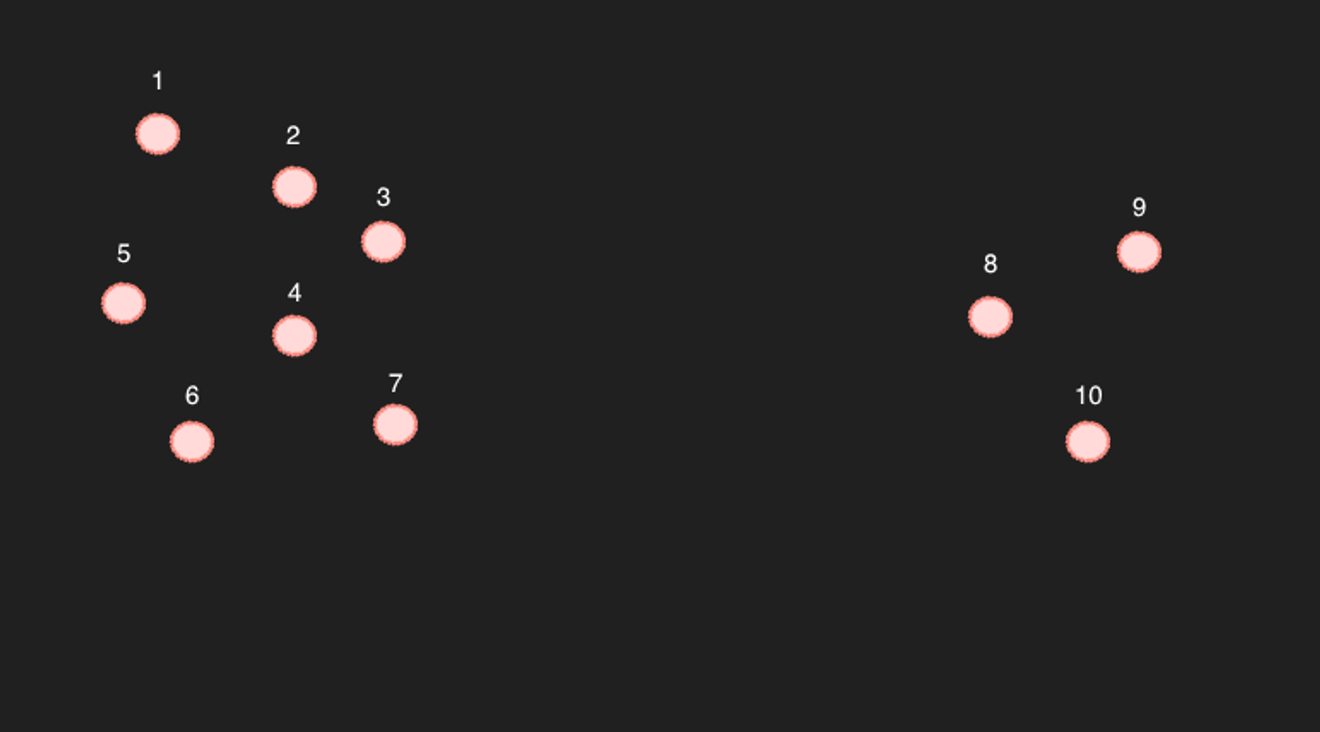
ลองยกตัวอย่าง 10 จุดในพื้นที่ 2 มิติที่เรียบง่ายข้างต้น
จุดที่ 1-7 ถ้าเลือก 6 จุดที่ใกล้ที่สุด การเลือก 6 จุดที่เหลือเป็นจุดที่ใกล้ที่สุดนั้นชัดเจน (เป็นเช่นนั้นในแง่ของการคำนวณ)
ปัญหาอยู่ที่ 8-10... ตัวอย่างเช่น ถ้าคุณค้นหา 6 จุดที่ใกล้ที่สุดของหมายเลข 9 ผลลัพธ์น่าจะเป็น 8, 10 และ 3, 4, 7
แต่ถ้าเป็นเช่นนั้นก็เป็นปัญหา เพราะในทางกลับกัน ในหมายเลข 4 หมายเลข 9 ไม่รวมอยู่ใน 6 จุดที่ใกล้ที่สุด ดังนั้นมันจึงเป็นบทความที่เกี่ยวข้องกันหรือไม่?
ตัวอย่างข้างต้นเป็นกรณีที่รุนแรงมาก แต่ถ้ามีจุดมากพอที่จะไม่มีช่องว่างกว้างๆ แบบนั้น มันก็อาจจะถือว่าอยู่ใกล้กันได้ (แต่ถ้าคิดถึงมิติที่ 768 มันก็มีช่องว่างอยู่ระหว่างจุดอยู่ดี ถ้าไม่มีบทความมากพอ...)
ฉันกำลังคิดอยู่ แต่สิ่งที่แน่นอนที่สุดคือปัญหาจะได้รับการแก้ไขหากมีบทความมากพอ?
June 18, 2024
April 11, 2024
September 4, 2024
January 18, 2025
January 15, 2025
April 9, 2025
ความคิดเห็น0