Тема
- #Векторный поиск (Vector Search)
- #Поиск по схожести
- #Распределение данных
- #Многомерное пространство
- #Поиск ближайшего соседа
Создано: 2024-11-23
Создано: 2024-11-23 17:13
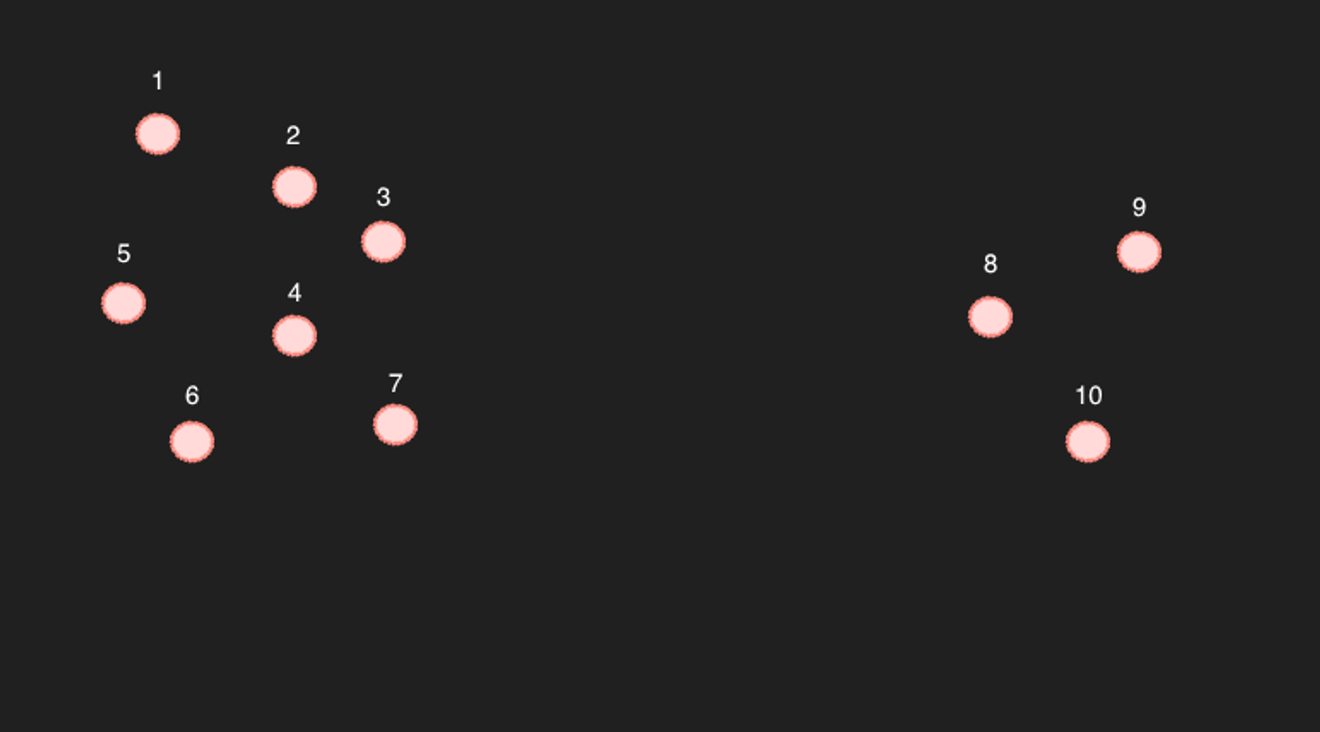
Пример распределения
Основа векторного поиска (далее — поиск) заключается в поиске ближайших объектов с помощью различных математических методов.
Однако, меня вдруг посетил вопрос. Действительно ли поиск ближайших соседей, безусловно, верен и математически корректен, но является ли это поиском похожих записей?
В действительности, поиск, используемый в durumis (Дурумис), представляет собой поиск 6 ближайших записей в 768-мерном пространстве для одной записи.
Однако, у меня возникли сомнения относительно того, действительно ли похожие записи являются похожими. (Поскольку иногда встречаются не похожие записи...)
В чём же причина?
Возьмём в качестве примера 10 точек в упрощённом двумерном пространстве.
Для точек с 1 по 7, при выборе 6 ближайших точек, остальные 6 точек, безусловно, будут обозначены как ближайшие. (Это подтверждается расчётами.)
Проблема в точках с 8 по 10... Например, если найти 6 ближайших к точке 9 точек с помощью поиска, то это будут точки 8, 10, а также 3, 4, 7.
Но в этом-то и проблема, ведь в свою очередь, точка 9 не входит в 6 ближайших к точке 4, так являются ли они действительно связанными записями?
Приведённый выше пример является довольно крайним случаем, но если достаточно много точек, и нет таких больших пустых пространств, то их можно считать достаточно близкими. (Однако, учитывая 768-мерность, между точками неизбежно будут существовать пустые пространства. Если записей не так уж много...)
Я размышляю над этим, но самый надёжный способ — это заполнение достаточного количества записей, и тогда эта проблема решится?
June 18, 2024
March 29, 2024
March 13, 2024
April 25, 2024
September 4, 2024
August 7, 2024
Комментарии0