Assunto
- #Espaço de alta dimensão
- #Busca do mais próximo
- #Busca Vetorial
- #Distribuição de dados
- #Busca de similaridade
Criado: 2024-11-23
Criado: 2024-11-23 17:13
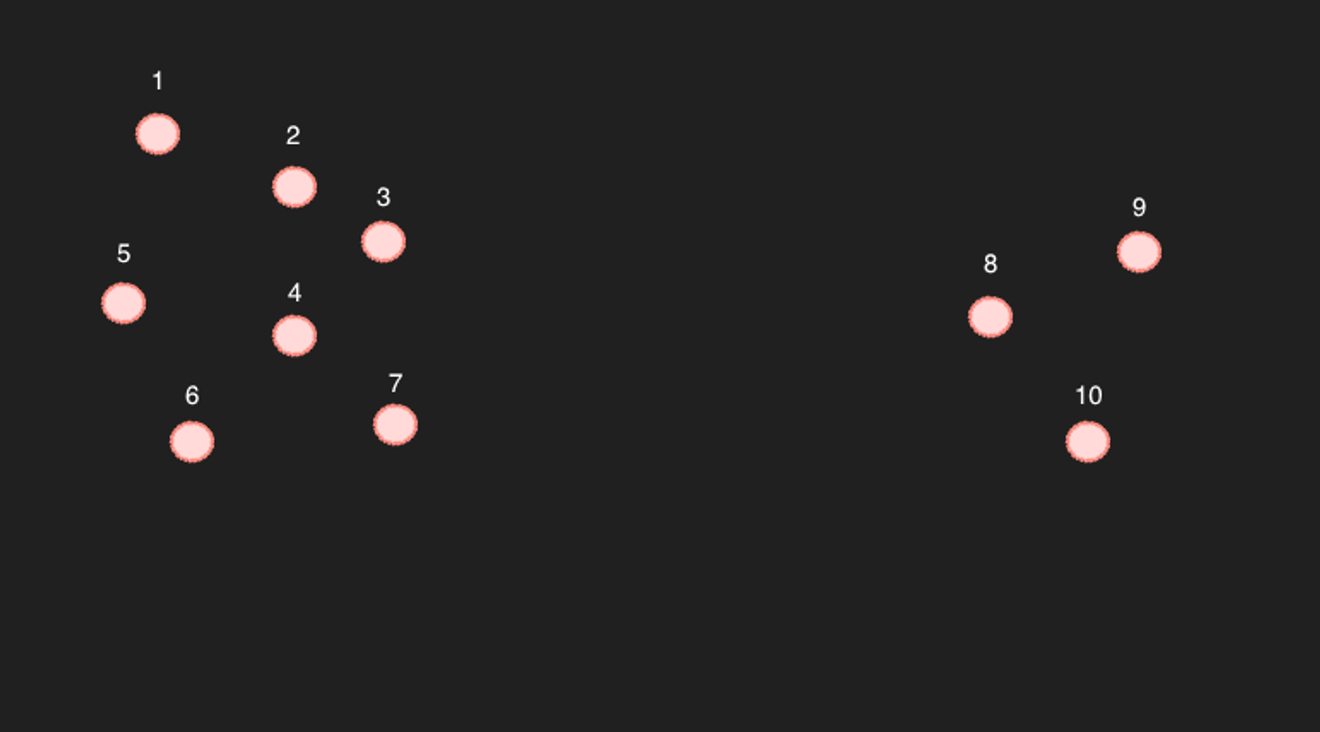
Amostra de dispersão
A base da Busca Vetorial (doravante, busca) é encontrar itens próximos uns dos outros por meio de diversos métodos matemáticos.
No entanto, surgiu uma dúvida. Será que a busca pelo item mais próximo está correta, tanto na prática quanto matematicamente, mas será que isso significa que os artigos são realmente similares?
Na verdade, a busca usada no durumis busca os 6 artigos mais próximos de um artigo específico em um espaço de 768 dimensões.
Mas, comecei a questionar se os artigos similares são realmente similares. (Às vezes, artigos não similares aparecem...)
Então, qual é a razão?
Vamos usar como exemplo 10 pontos em um espaço bidimensional simplificado.
Para os pontos de 1 a 7, é claro que, se selecionarmos os 6 pontos mais próximos, os outros 6 serão os pontos mais próximos. (Isso é verdade também em termos de cálculo)
O problema são os pontos de 8 a 10... Por exemplo, se procurarmos os 6 pontos mais próximos do ponto 9, provavelmente serão 8, 10 e 3, 4, 7.
Mas aí está o problema: inversamente, o ponto 9 não está incluído entre os 6 pontos mais próximos do ponto 4. Então, eles são realmente artigos relacionados?
O exemplo acima é um caso bastante extremo. Se houver pontos suficientes para que não haja grandes espaços vazios, podemos considerá-los próximos o suficiente. (No entanto, considerando que temos 768 dimensões, é inevitável que existam espaços vazios entre os pontos. A menos que haja muitos artigos...)
Estou pensando nisso, mas a maneira mais confiável é que este problema será resolvido se houver artigos suficientes, certo?
June 18, 2024
April 11, 2024
April 26, 2024
September 4, 2024
April 25, 2024
May 31, 2024
Comentários0