主題
- #データ分布
- #Vector Search
- #類似度検索
- #最隣接検索
- #高次元空間
作成: 2024-11-23
作成: 2024-11-23 17:13
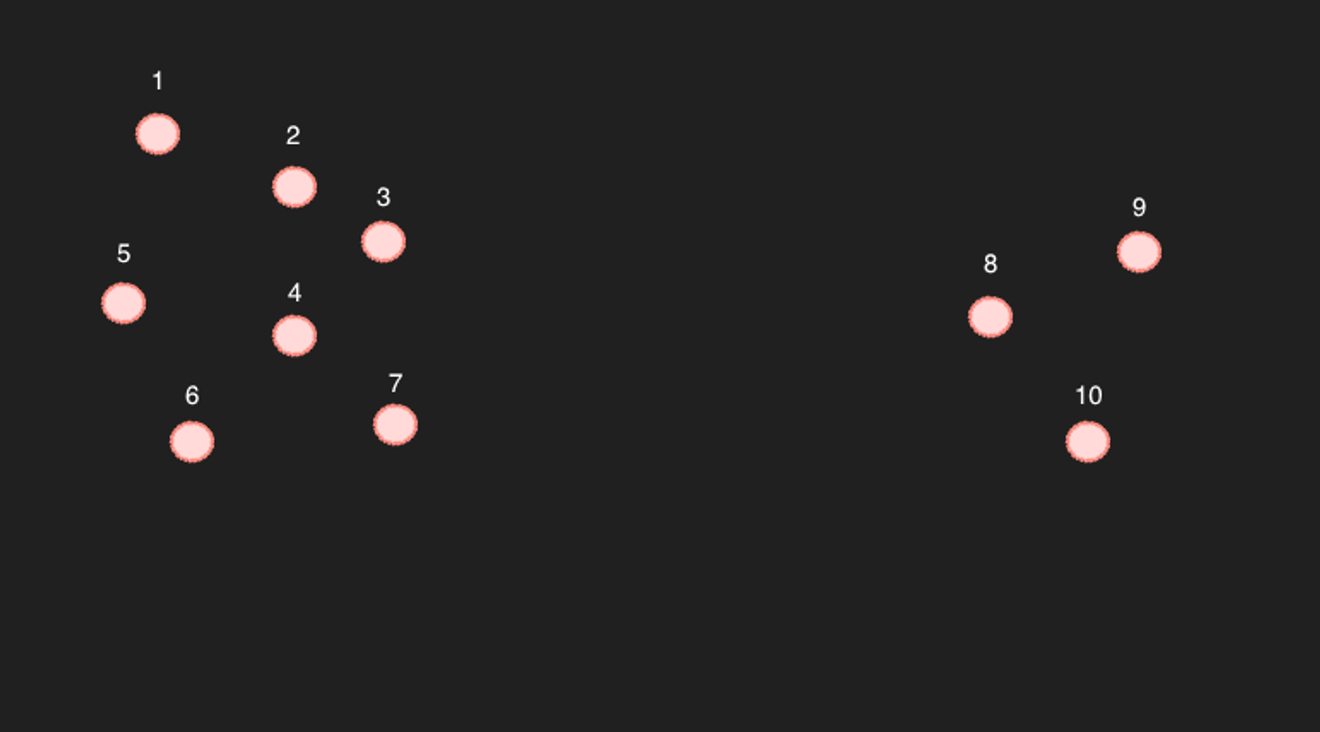
分散のサンプル
ベクトル検索(以下、検索)の基本は、様々な数学的手法を用いて、近い距離にあるものを探すことです。
ところが、ふと疑問が湧きました。確かに最近傍検索は正しく、数学的にも正しいのですが、これが本当に類似記事と言えるのでしょうか?
ドゥルミスで実際に使用している検索は、1つの記事を768次元の空間で最も近い6つの記事を検索する方法です。
しかし、類似記事が本当に類似記事なのかどうかについて疑問を持つようになりました。(時々、似ていない記事も出てくるので…)
では、その理由は何か?
上記の単純化された2次元空間の10個の点を例に挙げてみましょう。
1~7番の点は、確かに最寄りの6個の点を6個選択すれば、残りの6個が最も近い点として表示されることは間違いありません。(実際、計算上もそうです)
問題は8~10です…例えば、9番の最も近い6個の点を検索で見つけると、8、10、そして3、4、7になるでしょう。
すると、これが問題なのですが、逆に4番では最も近い6個の点に9番が含まれていません。果たして、互いに関連する記事と言えるのでしょうか?
上記の例はかなり極端なケースですが、もし十分に多くの点があり、そのような空いた空間が広く無ければ、十分に近くにあるとみなせるでしょう。(しかし、768次元であることを考えると、意外と途中に空いた空間が存在する可能性があります。本当に多くの記事があるわけではない限り…)
悩んでいますが、最も確実な方法は、十分な数の記事があればこの問題は解決するのではないでしょうか?
2025年1月18日
2024年3月13日
2024年6月18日
2024年5月31日
2024年4月11日
2024年4月25日
コメント0