Argomento
- #Ricerca Vettoriale
- #Distribuzione dei dati
- #Ricerca del più vicino vicino
- #Ricerca di similarità
- #Spazio multidimensionale
Creato: 2024-11-23
Creato: 2024-11-23 17:13
Esempio di dispersione
La base della Vector Search (di seguito, "ricerca") consiste nel trovare, attraverso diversi metodi matematici, gli elementi più vicini.
Tuttavia, mi sono posto una domanda. La ricerca dei più vicini è certamente corretta e matematicamente precisa, ma è effettivamente sinonimo di articoli simili?
In realtà, la ricerca utilizzata da durumis (두루미스) consiste nel cercare i 6 articoli più vicini a un dato articolo in uno spazio a 768 dimensioni.
Ma mi sono chiesto se gli articoli simili siano effettivamente simili. (A volte compaiono articoli non correlati...)
Qual è quindi la ragione?
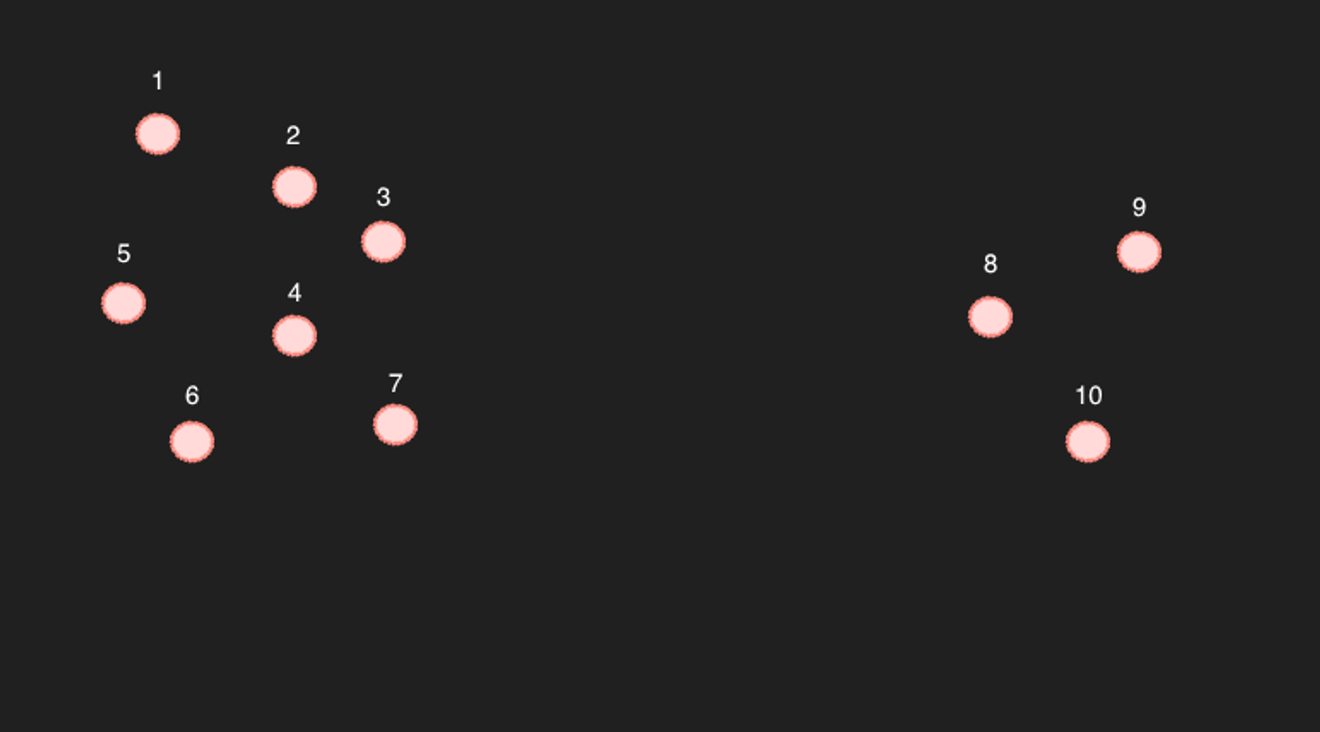
Prendiamo come esempio i 10 punti in uno spazio bidimensionale semplificato.
Per i punti da 1 a 7, selezionando i 6 punti più vicini, è certo che gli altri 6 punti saranno indicati come i più vicini. (È così anche da un punto di vista puramente matematico)
Il problema riguarda i punti da 8 a 10... Ad esempio, se si cercano i 6 punti più vicini al punto 9, si otterrebbero probabilmente gli 8, 10 e 3, 4, 7.
Ma questo è un problema: al contrario, nel punto 4, il punto 9 non è incluso tra i 6 punti più vicini. Quindi, sono effettivamente articoli correlati?
L'esempio sopra è un caso piuttosto estremo. Se ci fossero abbastanza punti da riempire gli spazi vuoti, potremmo considerare i punti vicini come effettivamente vicini. (Tuttavia, considerando le 768 dimensioni, è inevitabile che ci siano spazi vuoti. A meno che non ci siano molti articoli...)
Sto riflettendo, ma il modo più sicuro per risolvere questo problema è probabilmente quello di avere abbastanza articoli.
June 18, 2024
April 11, 2024
April 26, 2024
May 22, 2024
January 18, 2025
November 16, 2024
Commenti0